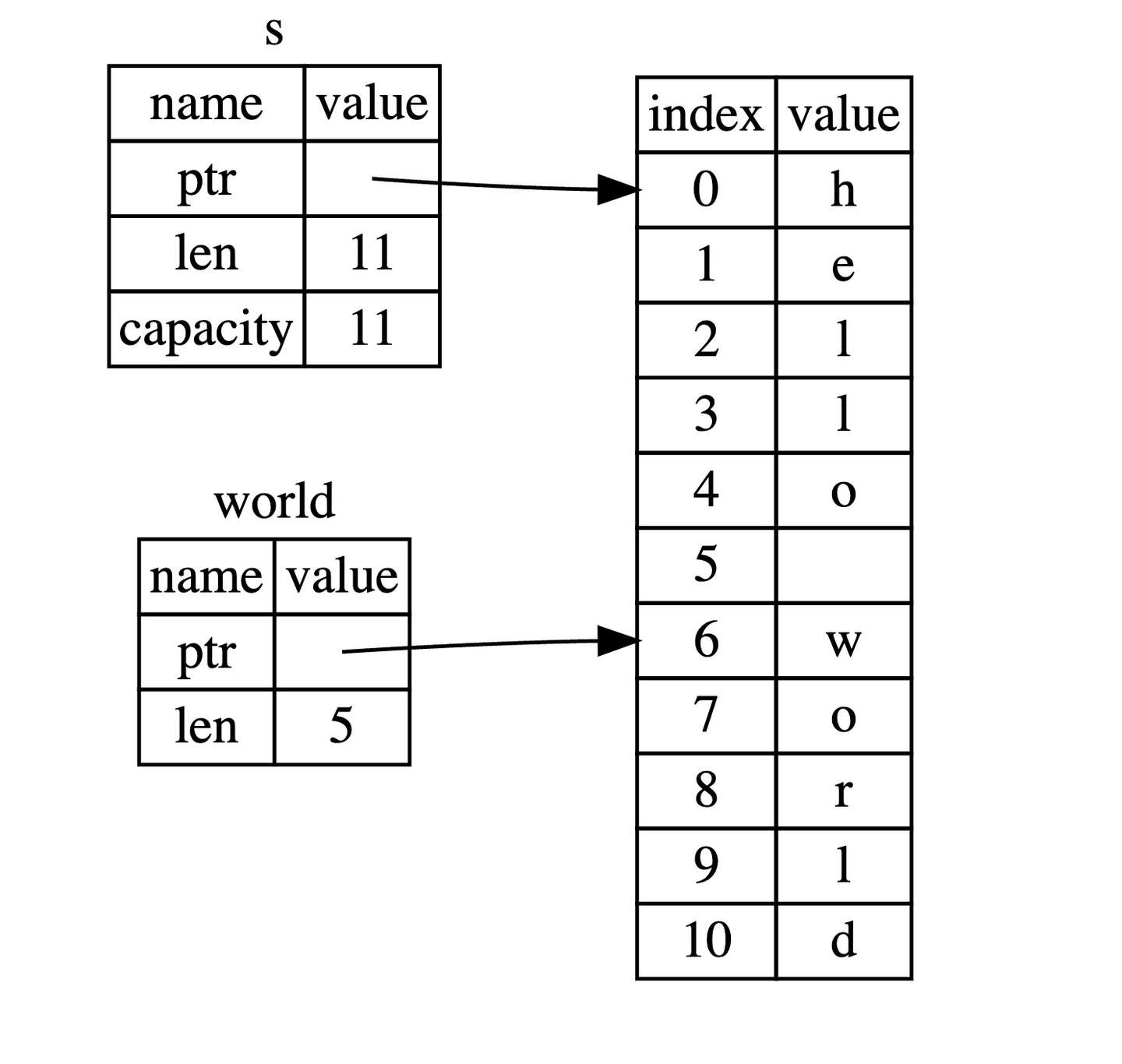
fn main() { let mut s = String::from("hello world"); let word = first_word(&s); s.clear(); // error! println!("the first word is: {}", word);}fn first_word(s: &String) -> &str { &s[..1]}
let mut s = String::from("Hello rust!");// 使用 insert() 方法插入单个字符 chars.insert(5, ',');// Hello, rust!// 使用 insert_str() 方法插入字符串字面量s.insert_str(6, " I like");// Hello, I like rust!
与追加一样,不会返回新的字符串,会修改原来的字符串。
替换
let old = String::from("哈xxx");// replace // 适用于 String 和 &str 类型// 第一个参数是要被替换的字符串,第二个参数是新的字符串// 返回一个新的字符串,而不是操作原来的字符串let new = old.replace("x", "Y");// YYYlet new = old.replace("哈", "Y");// Yxxx// replacen// 适用于 String 和 &str 类型// 前两个参数与 replace 方法一样,第三个参数则表示替换的个数// 返回一个新的字符串,而不是操作原来的字符串let new = old.replacen("x", "Y", 1);// 哈Yxx// replace_range// 仅适用于 String 类型// 第一个参数是要替换字符串的范围,第二个参数是新的字符串// 直接操作原来的字符串,不会返回新的字符串old.replace_range(4.., "Y");// 哈Y
删除
let mut s = String::from("rust pop 中文!");// pop// 删除并返回字符串的最后一个字符// 直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,告诉你删除字符let p = s.pop();// remove// 删除并返回字符串中指定位置的字符// 只接收一个参数,表示该字符起始索引位置// 直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串s.remove(0);// truncate// 删除字符串中从指定位置开始到结尾的全部字符// 直接操作原来的字符串。无返回值s.truncate(3);// clear// 清空字符串// 直接操作原来的字符串s.clear();
let s1 = "hello";let s2 = String::from("rust");let s = format!("{} {}!", s1, s2);
操作 UTF-8 字符串
// 以 Unicode 字符的方式遍历字符串for c in "你好".chars() { println!("{}", c);}// 返回字符串的底层字节数组for b in "你好".bytes() { println!("{}", b);}// 变长的字符串中获取子串// https://crates.io/crates/utf8_slice
字符串转义
通过转义的方式 \ 输出 ASCII 和 Unicode 字符。
// 通过 \ + 字符的十六进制表示,转义输出一个字符let byte_escape = "I'm writing \x52\x75\x73\x74!";println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);// \u 可以输出一个 unicode 字符let unicode_codepoint = "\u{211D}";let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";println!( "Unicode character {} (U+211D) is called {}", unicode_codepoint, character_name);// 换行了也会保持之前的字符串格式// 使用\忽略换行符let long_string = "String literalscan span multiple lines.The linebreak and indentation here ->\<- can be escaped too!";println!("{}", long_string);
在某些情况下,可能你会希望保持字符串的原样,不要转义
println!("{}", "hello \\x52\\x75\\x73\\x74");let raw_str = r"Escapes don't work here: \x3F \u{211D}";println!("{}", raw_str);// 如果字符串包含双引号,可以在开头和结尾加 #let quotes = r#"And then I said: "There is no escape!""#;println!("{}", quotes);// 如果字符串中包含 # 号,可以在开头和结尾加多个 # 号,最多加255个,只需保证与字符串中连续 # 号的个数不超过开头和结尾的 # 号的个数即可let longer_delimiter = r###"A string with "# in it. And even "##!"###;println!("{}", longer_delimiter);
fn main() { let tup: (i32, f64, char) = (42, 3.14, 'A'); // 定义一个包含i32, f64, 和char的元组 // 访问元组中的元素 let (x, y, z) = tup; // 解构元组 println!("x: {}, y: {}, z: {}", x, y, z); // 也可以直接通过索引访问元组元素 println!("The first element of the tuple is: {}", tup.0); // 输出42 println!("The second element of the tuple is: {}", tup.1); // 输出3.14}