关系数据库系统的查询处理
查询处理步骤
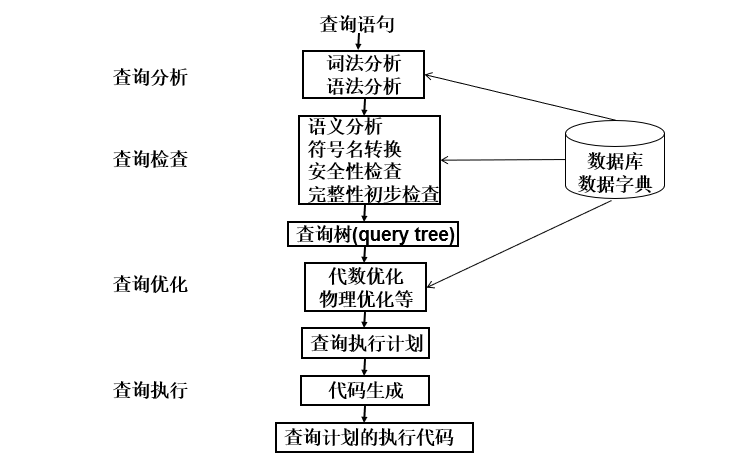
关系数据库管理系统查询处理阶段:
-
查询分析
任务:对查询语句进行扫描、词法分析和语法分析。
- 词法分析:从查询语句中识别出正确的语言符号;
- 语法分析:进行语法检查;
-
查询检查
任务:合法权检查,视图转换,安全性检查,完整性初步检查。
-
查询优化
选择一个高效执行的查询处理策略。
优化分类:
- 代数优化/逻辑优化:指关系代数表达式的优化
- 物理优化:指存取路径和底层操作算法的选择
查询优化的选择依据:
- 基于规则
- 基于代价
- 基于语义
-
查询执行
依据优化器得到的执行策略生成查询执行计划。
代码生成器生成执行查询计划的代码。
两种执行方法:自顶向下,自底向上。
实现查询操作的算法示例
-
选择操作的实现
-
全表扫描方法 (Table Scan)
对查询的基本表顺序扫描,逐一检查每个元组是否满足选择条件,把满足条件的元组作为结果输出。
适合小表,不适合大表。
-
索引扫描方法 (Index Scan)
适合于选择条件中的属性上有索引(例如B+树索引或Hash索引)。
通过索引先找到满足条件的元组主码或元组指针,再通过元组指针直接在查询的基本表中找到元组。
-
-
连接操作的实现
连接操作是查询处理中最耗时的操作之一 ,这里只讨论等值连接(或自然连接)最常用的实现算法 。
- 嵌套循环算法
- 排序—合并算法
- 索引连接算法
- Hash Join算法
关系数据库系统的查询优化
查询优化在关系数据库系统中有着非常重要的地位。
关系查询优化是影响关系数据库管理系统性能的关键因素。
由于关系表达式的语义级别很高,使关系系统可以从关系表达式中分析查询语义,提供了执行查询优化的可能性。
查询优化概述
关系系统的查询优化是关系数据库管理系统实现的关键技术又是关系系统的优点所在,减轻了用户选择存取路径的负担。
查询优化的优点:
- 用户不必考虑如何最好地表达查询以获得较好的效率
- 系统可以比用户程序的“优化”做得更好
关系数据库管理系统通过某种代价模型计算出各种查询执行策略的执行代价,然后选取代价最小的执行方案。
查询优化的总目标:
- 选择有效的策略
- 求得给定关系表达式的值
- 使得查询代价最小(实际上是较小)
代数优化
关系代数表达式等价变换规则
代数优化策略:通过对关系代数表达式的等价变换来提高查询效率。
关系代数表达式的等价:指用相同的关系代替两个表达式中相应的关系所得到的结果是相同的。
两个关系表达式和是等价的,可记为。
常用的等价变换规则:
-
连接、笛卡尔积交换律

-
连接、笛卡尔积的结合律

-
投影的串接定律
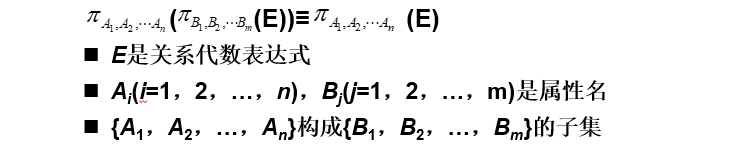
-
选择的串接定律

-
选择与投影操作的交换律

-
选择与笛卡尔积的交换律

-
选择与并的分配律

-
选择与差运算的分配律
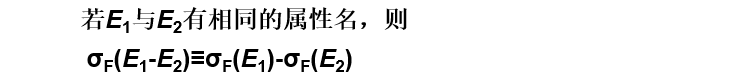
-
选择对自然连接的分配律
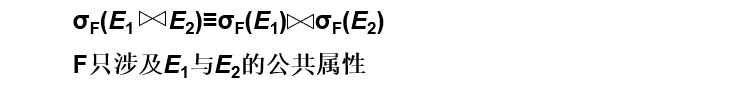
-
投影与笛卡尔积的分配律

-
投影与并的分配律

查询树的启发式优化
典型的启发式规则:
-
选择运算应尽可能先做
在优化策略中这是最重要、最基本的一条。
-
把投影运算和选择运算同时进行 如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时完成所有的这些运算以避免重复扫描关系。
-
把投影同其前或其后的双目运算结合起来,没有必要为了去掉某些字段而扫描一遍关系。
-
把某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算,连接特别是等值连接运算要比同样关系上的笛卡尔积省很多时间。
-
找出公共子表达式
如果这种重复出现的子表达式的结果不是很大的关系并且从外存中读入这个关系比计算该子表达式的时间少得多,则先计算一次公共子表达式并把结果写入中间文件是合算的。
当查询的是视图时,定义视图的表达式就是公共子表达式的情况
物理优化
代数优化改变查询语句中操作的次序和组合,不涉及底层的存取路径。
对于一个查询语句有许多存取方案,它们的执行效率不同, 仅仅进行代数优化是不够的。
物理优化就是要选择高效合理的操作算法或存取路径,求得优化的查询计划。
物理优化方法:
-
基于规则的启发式优化
启发式规则是指那些在大多数情况下都适用,但不是在每种情况下都是适用的规则。
-
基于代价估算的优化
优化器估算不同执行策略的代价,并选出具有最小代价的执行计划。
-
两者结合的优化方法
常常先使用启发式规则,选取若干较优的候选方案,减少代价估算的工作量,然后分别计算这些候选方案的执行代价,较快地选出最终的优化方案 。
基于启发式规则的存取路径选择优化
-
选择操作的启发式规则
对于小关系,使用全表顺序扫描,即使选择列上有索引。
对于大关系,启发式规则有:
-
对于选择条件是“主码=值”的查询
查询结果最多是一个元组,可以选择主码索引。一般的关系数据库管理系统会自动建立主码索引。
-
对于选择条件是“非主属性=值”的查询,并且选择列上有索引
要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法,否则还是使用全表顺序扫描。
-
对于选择条件是属性上的非等值查询或者范围查询,并且选择列上有索引
要估算查询结果的元组数目,如果选择率<10%,可以使用索引扫描方法,否则还是使用全表顺序扫描。
-
对于用AND连接的合取选择条件
如果有涉及这些属性的组合索引,优先采用组合索引扫描方法。 如果某些属性上有一般的索引,可以用索引扫描方法。
其他情况:使用全表顺序扫描。
-
对于用OR连接的析取选择条件,一般使用全表顺序扫描
-
-
连接操作的启发式规则
- 如果2个表都已经按照连接属性排序,选用排序-合并算法
- 如果一个表在连接属性上有索引,选用索引连接算法
- 如果上面2个规则都不适用,其中一个表较小,选用Hash join算法
- 可以选用嵌套循环方法,并选择其中较小的表,确切地讲是占用的块数较少的表,作为外表(外循环的表) 。
基于代价的优化
启发式规则优化是定性的选择,适合解释执行的系统。解释执行的系统,优化开销包含在查询总开销之中 。
编译执行的系统中查询优化和查询执行是分开的,可以采用精细复杂一些的基于代价的优化方法。
-
统计信息
基于代价的优化方法要计算查询的各种不同执行方案的执行代价,它与数据库的状态密切相关 。
优化器需要的统计信息:
- 对每个基本表:该表的元组总数(N),元组长度(l),占用的块数(B),占用的溢出块数(BO)
- 对基表的每个列:该列不同值的个数(m),列最大值和最小值,列上是否已经建立了索引,哪种索引,可以计算选择率(f)
- 对索引:索引的层数(L),不同索引值的个数,索引的选择基数S(有S个元组具有某个索引值),索引的叶结点数(Y)
-
代价估算示例
-
全表扫描算法的代价估算公式
如果基本表大小为B块,全表扫描算法的代价 cost=B。如果选择条件是“码=值”,那么平均搜索代价 cost=B/2。
-
索引扫描算法的代价估算公式
如果选择条件是“码=值”,则采用该表的主索引。若为B+树,层数为L,需要存取B+树中从根结点到叶结点L块,再加上基本表中该元组所在的那一块,所以cost=L+1。
如果选择条件涉及非码属性。若为B+树索引,选择条件是相等比较,S是索引的选择基数(有S个元组满足条件),满足条件的元组可能会保存在不同的块上,所以(最坏的情况)cost=L+S。
如果比较条件是>,>=,<,⇐操作。假设有一半的元组满足条件,就要存取一半的叶结点,通过索引访问一半的表存储块,cost=L+Y/2+B/2。如果可以获得更准确的选择基数,可以进一步修正Y/2与B/2。
-
嵌套循环连接算法的代价估算公式
嵌套循环连接算法的代价cost=Br+BrBs/(K-1)。如果需要把连接结果写回磁盘,cost=Br+Br Bs/(K-1)+(FrsNrNs)/Mrs。其中Frs为连接选择性,表示连接结果元组数的比例; Mrs是存放连接结果的块因子,表示每块中可以存放的结果元组数目;
-
排序-合并连接算法的代价估算公式
如果连接表已经按照连接属性排好序,则cost=Br+Bs+(FrsNrNs)/Mrs。如果必须对文件排序,还需要在代价函数中加上排序的代价,对于包含B个块的文件排序的代价大约是。
-